class: center, middle # Character Set Encoding and Why You Should Care --- # Getting on the Same Page * Character set defines what characters are supported. The only true character set that you will probably encounter is Unicode. * Character set encoding defines what characters are supported **AND** their binary representation. Examples include EBCDIC, ASCII, ISO-8859-1, Windows 1250, UTF-8, UTF-16. Commonly interchanged with Character set. * Character font defines the visual appearance of characters. Few fonts cover the full Unicode set. --- # Are You Feeling Lucky? * Do you only use the characters on a standard US keyboard in a homogeneous environment (no or all IBM iSeries)? * Do you only use modern software with proper storage formats (prescribed or self-described encoding)? * Otherwise, you need to pay attention when: * Exchanging data across programs * Exchanging data across operating systems * Exchanging data across countries * Exchanging data across computers controlled by people who don't accept the defaults --- # What the problem looks like: * What you want <br/>  * What you get (UTF-8 viewed as 8859-1) <br/> 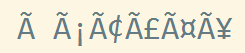 * What you get (8859-1 viewed as UTF-8) <br/> 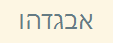 or maybe  <br/><br/><br/>comparison images generated in notepad++ --- # How did we get here? * Started with 7-bit ASCII (except for IBM who wanted/needed EBCDIC) * 8th bit used to support additional languages (ISO-8859-?, Windows code pages) * Double Byte Character Sets (1st good support for Asian characters) * UTF-8, UTF-16, UTF-7, ... ??? Original SMTP specification explicitly limits lines to 1000 characters or less of 7-bit US ASCII EBCDIC has backwards compatibility with punch cards --- # My Advice * Choose your own default rather than passively accept your programing language default * Prefer established libraries over custom code * When in doubt, use UTF-8 * ASCII text is legal UTF-8 * UTF-8 doesn't care about big-endian vs little-endian * UTF-8 is multi-byte for full Unicode coverage * UTF-8 is the default for most (if not all) programs that support Unicode ??? defaults are often system dependent, which will eventually be a rude surprise who would guess that JSON has to be UTF-8, UTF-16, UTF-32 --- # No one listens to me * application/json is UTF-8 (default), UTF-16 or UTF-32 with no byte order mark * HTTP Content-Length header is number of octets, not characters * HTTP Content-Type header should specify encoding if other than 8859-1 (commonly abused)